EDITOR’S NOTE: We’ve blogged before about the awkward – and often inappropriate – mismatch between the nature of most “generative AI” tools and the actual needs of the human service sector and the people being served by them. Specifically, these tools work with probabilistic patterns of language: they produce plausible sentences, which is not the same thing as reliable information. Without a reliable supply of human-assured data, they simply can’t be trusted to help vulnerable people in need.
That’s not to say it’s all a total bust. We’ve featured examples of promising use cases for AI tools here on the blog. They just don’t look like AI replacing humans in producing information, much less helping people find and use information. Rather, as pattern-recognition tools, these tools can usefully help humans work with common patterns in data management.
Here on our blog today we share a great example from Connect211, who recently told us about their new Record Matcher tool – which they have since shared as open source software. In this new post, originally shared on their blog, CEO Skyler Young tells us about how they’ve built a cyborg system that helps resolve one of the oldest problems in the human service information-and-referral field: redundant directory data silos.
This new Record Matcher tool is building a machine-learning model that can be used to instantaneously compare different datasets containing redundant information, in order to help resource data managers figure out which records are actually about the same organizational entity. This is harder than it sounds – as the post below explains in copious detail – but these new AI tools are making it much much easier. In turn, this is unlocking new possibilities for cooperation among organizations that have previously been locked in wasteful competitive databasing for generations. This is the kind of nerdery that we get really excited about.
So check out the post below – and their Github repo, if you’re technically inclined. We’ll share more details soon, but reach out in the meantime if you have any questions or suggestions.
Thanks for bearing with us through this long introduction. Take it away, Skyler!
On Open Referral’s blog, we recently posted about our Resource Record-Matcher: an open source AI-powered directory data collaboration tool.
As I wrote there, “At Connect211, we work with human service referral providers in more than twenty states to ‘orchestrate’ resource data pipelines, and support directory services. In areas where we serve multiple clients, and/or help them collaborate with their partners, we also facilitate collaboration across redundant yet siloed directory systems.”
We’ve seen many reasons that directories might choose to collaborate, including:
- Providing broader geographic coverage for directory and referral services
- Coordinating work to reduce maintenance costs
- Crowdsourcing quality-improvement feedback
In order to collaborate, directories need to compare their data, rapidly assessing where they overlap and what unique resources or features they provide. This is where Connect 211’s Record Matcher tool comes in. Using a process called “entity resolution”, the Record Matcher walks users through verifying which Organizations and Services are the same between directories.
Record Matcher reduces the time required to compare data sets by days or even weeks. I think that’s pretty exciting, and I want to share a bit more about how we’ve done it.
The challenge: “sameness” is a matter of opinion.
We’ve discovered that the question “Are these entities the same?” is usually a matter of opinion. Take organizations, for example. It’s easy to think of them as recognizable brands with official names and even tax identification numbers that make them unique and easy to distinguish. However, the same organization might be referred to by different names in different contexts.
Furthermore:
- Large organizations may sub-organizational entities that are essentially their own institutions.
- Government agencies don’t have unique IDs, and also frequently oversee programs or departments that overlap in irregular ways.
- Local data stewards sometimes separate organizations into separate entities based on regional offices or contacts.
These are just a few reasons there may not be a single right answer to the question of “Are these the same?”
We predict that effective entity-resolution and data-collaboration tools will facilitate the gradual alignment of perspectives on what constitutes a unique entity – though such perspectives may never completely converge. Legitimate differences of opinion about the boundaries around entities will remain. Our goal is not to eliminate opinions by establishing an objective truth, but rather to improve our capacity to cooperate and manage divergent opinions.
The role of (legally) objective facts in entity resolution.
Some kinds of data really are objective: legally verifiable facts. Phone numbers, URLs, email addresses, physical addresses, and external organization identifiers are all formally knowable in that they are governmentally known, rather than matters of perspective which people might reasonably disagree about. Formatting specifics (like “Street” vs “St,” or whether a URL has “www” or not) might still vary across datasets, but for trained AI models these differences are increasingly trivial to resolve.
As such, these legally objective facts play a key role in determining what entities are the “same.” Combined with semantic (AI) comparisons, we are able to find duplicates even among records with very different names.
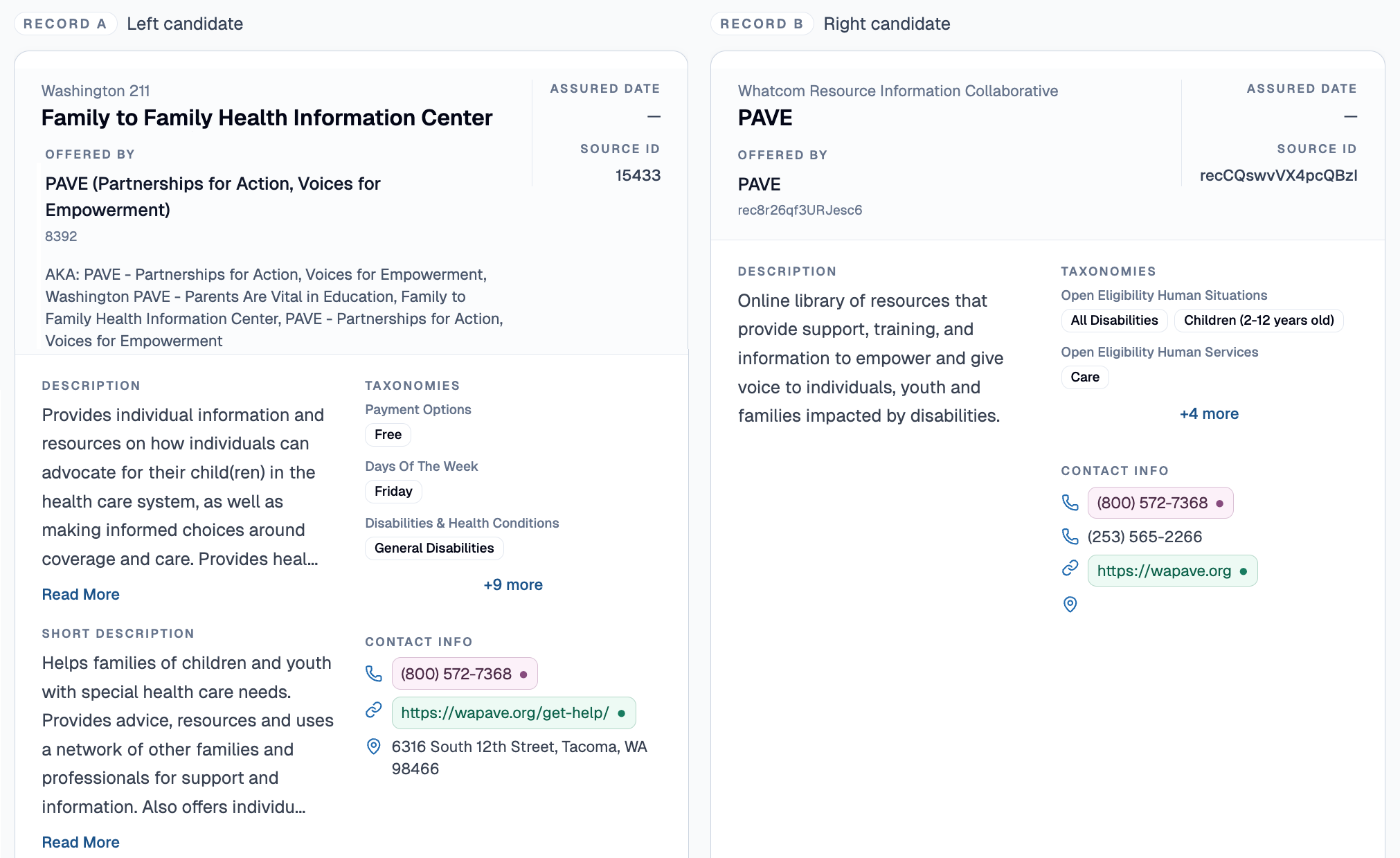
Resolving fuzzily redundant services.
The most important entities that we have focused on resolving are services: Vital resources in our communities. There is a wide array of opinions about how to define “service.” For example, some directories define services in a very granular way, while others bundle related concepts together in longer descriptions. This results in the same cluster of activities defined as a single record in one system and five records in another.
To resolve services, we look for four categories of things they have in common:
- A parent organization
- Objectively factual data like phone numbers, addresses, etc
- Categories and taxonomies, also known as Service Terms for many 211s
- Semantic similarity in key fields like names and descriptions
#1 is actually not as useful as you’d expect, because organization names can vary significantly. And organization and service resolutions may align unevenly based on presentational requirements: sometimes organizations partner with each other, for instance, or are co-located, in ways that matter more or less to different kinds of users. It’s messy! We want to get better at figuring this out, too, but in the meantime our clients’ top priority is usually improving the quality of service-level information which is what their users really need.
So our current method primarily leverages #2, and then draws inference from #3 and #4.
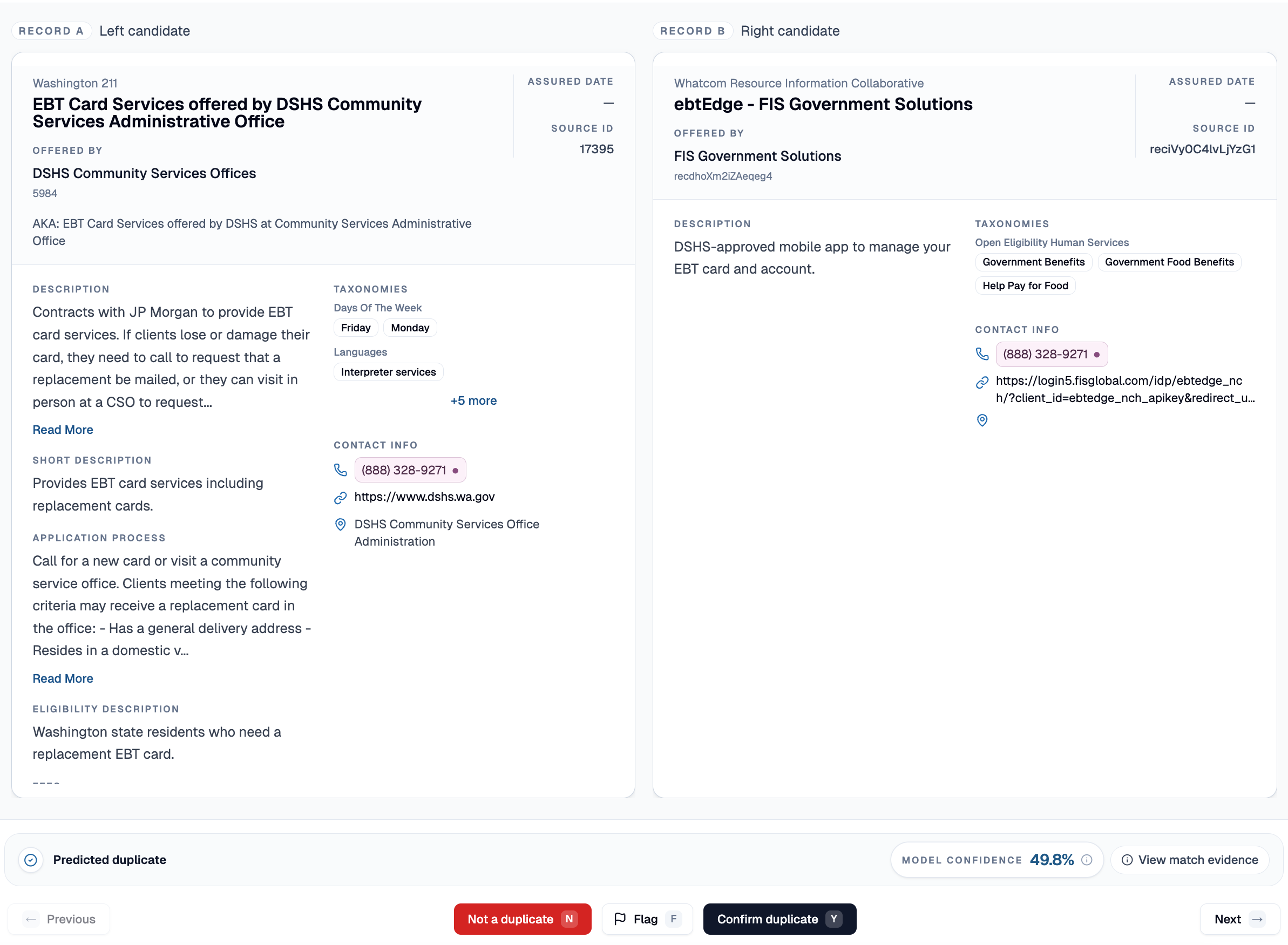
Resolving similar categories from different taxonomies.
Categories, like those used in taxonomic schema, provide incredibly valuable signals for comparing and resolving services; when two services from different sources share related taxonomy terms or categories, there is a stronger basis for comparison. Categories themselves need to be resolved in order to facilitate that value.
Unlike other entities studied, taxonomies (also known as “indexing systems”) do not have internal duplication. Within a single taxonomy, each term is (at least in principle) distinct. This makes resolving related taxonomies across different sources more of a crosswalk process.
Consensus on how terms should be mapped varies, and we must design for multiple concurrent answers. That said, broad adoption of standard taxonomic mappings across major indexing systems is one of the best ways to improve entity resolution.
Lessons learned resolving Organizations.
Initially, we tried to match organizations as a precursor and aid for matching services. Two things changed our mind:
- As mentioned earlier, organizations were harder than expected to resolve. Their boundaries (whether by domain, description, or geography) vary widely between directories.
- We eventually discovered we could resolve services without first resolving organizations.
We decided to punt organization resolution for this round of development, but not before mapping out plans for the future.
We think the best approach is to create “global” organization records that require legal identifiers such as FEINs (where possible), which we can then associate to subsidiary organizations, like an umbrella. This approach would preserve the fidelity of individual data sources while also aligning them globally. Whether there is value in hard-aligning services to those mapped organizations is an open question in our team. Regardless, this method would balance the benefits of aggregation while preventing the collapse of localized distinctions for organizations.
Humans Still Need to Make the Decisions
All of this modeling and mechanical analysis is, at best, only useful to the extent that it helps knowledgeable humans make faster and more effective decisions. It’s actually people who resolve the identities, and our tools just help them do that more efficiently. Humans remain in the loop for critical steps:
- Verify or correct our tool’s proposed pair-wise groupings. AI does get it wrong sometimes. So our tools are designed to present possible matches for human review. This requires way less effort than doing the comparison manually.
- Prioritize data in the final, reconciled result based on the subjective requirements of a target audience. Only humans know what’s important.
Humans are also irreplaceable (it turns out) for gathering resource information in the first place – which is to say: as impressive as our AI tooling is, it depends the expertise and relationships that our clients offer their communities, by which they aggregate directory data. But that’s for another article.
What Comes Next?
After identifying which entities are the same (and verifying the results), the next step is to reconcile groups of the same entities so that the resulting outputs, such as a resource directory database, don’t display duplicates to users. This is a key step in synthesizing diverse data sources while preserving consistency and usability for people seeking information.
Reconciliation is a complicated topic with many potential solutions that are outside the scope of this article. If you would like to learn more, we will describe a solution that we are currently developing in the next blog post: A Minimal Approach to Deduplicating Services in Resource Directories
The State Of This Project
Through pilot projects in Washington State and Illinois, we have progressed at a breakneck pace since 2022. Early prototypes were simple proof-of-concepts. As of 2026 we are running a beautiful user interface that is integrated into the enterprise-grade data orchestration from Connect 211. We have also started releasing our code:
- The model we use for entity resolution is available on Hugging Face.
- The Python Package that embeds this model within our orchestration pipeline is available for reference on Github as well.
Work is ongoing as we shift from experimentation into enterprise data federation and collaboration infrastructure. Our years of pilots have informed a clearer understanding of how to turn multiple overlapping data sources into a scalable system.
As work continues, we are actively looking for:
- More pilot opportunities
- Funders
- Collaborators
We are unlocking the ability to create supply chains for resource data and reducing the number of overlapping data silos that currently dot our resource directory landscape. This may be relevant to Rural Health Transformation Projects, bringing more accurate directory data to areas that tend to be sparsely served and less connected. The ripple effect is huge.
Please reach out to [email protected] to learn more and collaborate.
Leave a Reply